-
DS스쿨 데이터사이언스 입문반 3주차 후기(비전공자)Data Analysis/DS SCHOOL 2020. 5. 31. 16:10
DS스쿨에서 데이터사이언스 과정 중 데이터 분석 입문 과정을 듣고 있다. 매일 조금씩 데이터 분석을 공부한다. 물론 수업 전 후가 가장 활발하다. 커리큘럼은 재밌다. 비전공자이지만 도전해볼 만한 여지를 주기 때문이어서다. 어서 데이터에 익숙해지길 바랄 뿐이다. 3주차 수업을 듣고 난 후에는 조금 더 재미가 붙었다. 역시 여러 번 듣는 것이 나에겐 중요한 것 같다.
3주차에서 중요한 것은 역시나 검색의 중요성, 그리고 맛보기로 배웠지만 '탐험적 데이터 분석'의 개념이다.
코딩은 시간이 지나면 익숙해진다고 하셨다. 다만 데이터를 다양한 관점에서 보는 눈은 키워야 하고, 그것에 분석의 핵심이라고 하셨다. 이해가 됐다. 코딩으로 인한 불안감은 잠시 접어 두고, 나만의 뾰족한 통찰력을 키우는 데 집중해야 할 필요를 느꼈다. 그래서 내 분야가 있어야 한다는 이야기 같다.
3주차는 케글의 바이크 쉐어링 수요 예측을 해본다.
요런 화면이다.
예측을 효과적으로 하기 위해 seaborn이라는 툴을 배웠다. pandas로 표를 정돈했다면 seaborn은 그것을 그래프로 시각화 해주는 기능을 한다. 코드를 치면 형형색색의 그래프가 쫙 하고 나오는 것이 신기했다.
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2)
# 전체 화면 피규어로 받고 구역별 지정해준 것 2열 3행. 아래 받은대로 지정해주기
figure.set_size_inches(18, 8)
# 사이즈 지정하는 코드.
sns.barplot(data=train, x='year', y='count', ax=ax1)
sns.barplot(data=train, x='month', y='count', ax=ax2)
#여름에 전반적으로 높아진다. 2, 3, 4 월에 여름보다 가파르다. 12월과 1월이 왜 차이날까? 붙어 있는데.
sns.barplot(data=train, x='day', y='count', ax=ax3)
sns.barplot(data=train, x='hour', y='count', ax=ax4)이렇게 코드를 입력하면..
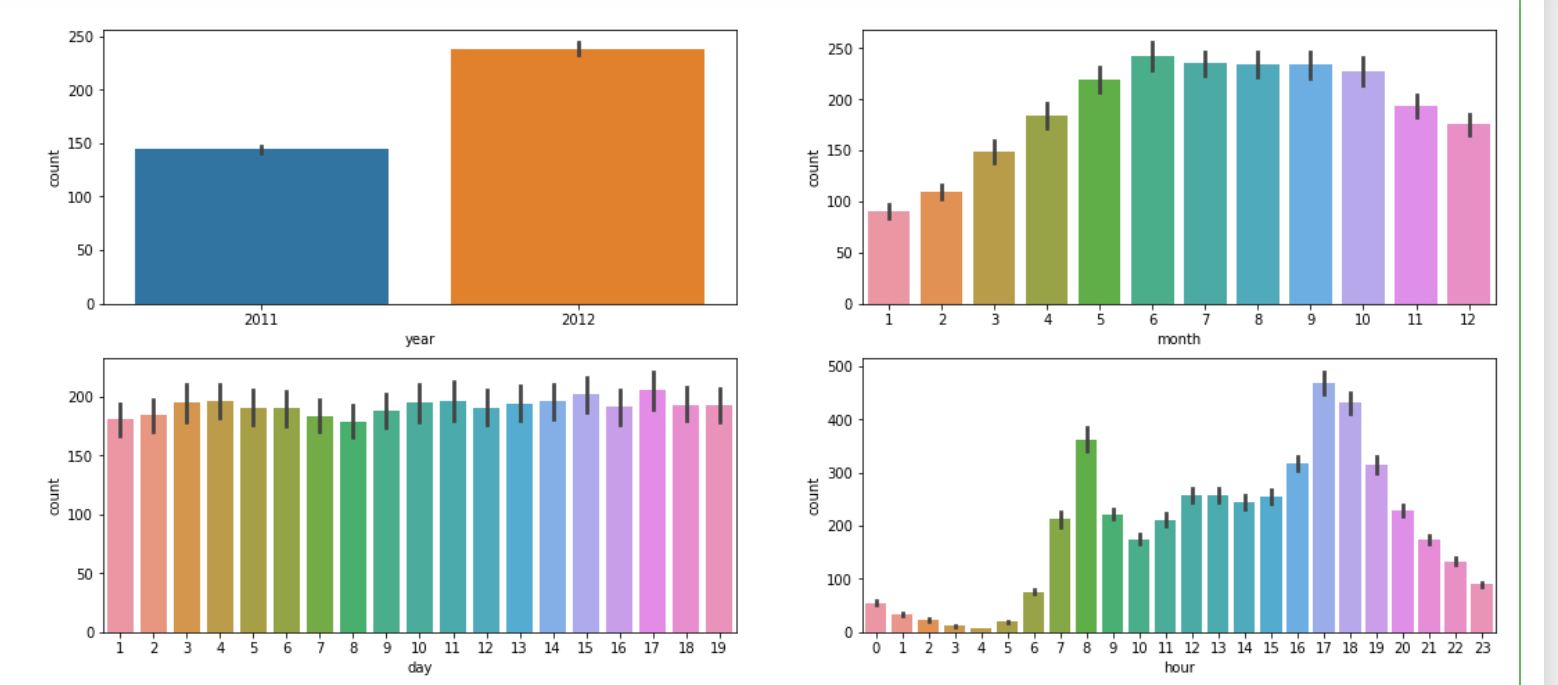
이렇게 나왔다. 물론 감탄만 하고 있으면 말짱 꽝이다.
확연히 변화를 짚어낼 수 있는 요소를 찾아서 그것에 맞게 데이터를 편집해야 한다.
편집 후 에 머신러닝이라는 알고리즘에 넣어서 예측을 하는 것이 데이터 분석의 한 과정이라고 배웠다.
여기서 중요한 것은 수치를 하나만 보는 것을 경계하는 것이다. 평균, 편차, 갯수 등 적어도 세 개 이상은 봐야 한다.
다음은 datetime을 변경했다.
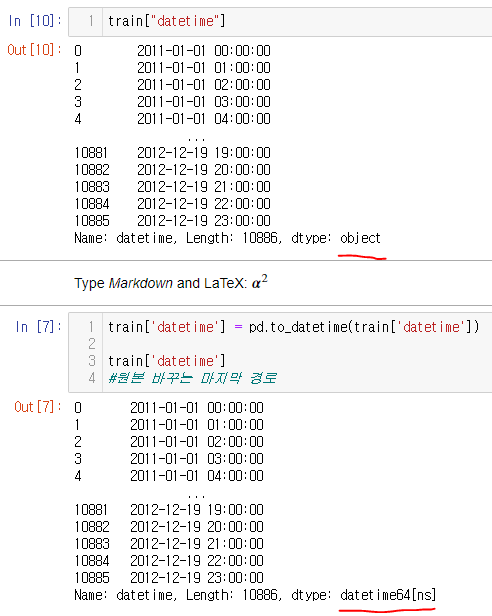
문자형 이었던 날짜데이터를 판다스 기능으로 아예 날짜 형태로 바꿨다. 특이하고도 재밌는 기능이다.
이제 날짜를 분리한다.

train, test를 같이 분리해 주는 것이 중요하다.
이렇게 전처리를 마쳤으면 머신러닝 알고리즘을 돌려서 test파일에는 없는 count를 예측해주면 된다.
예측 구조는 feature(예측에 사용될 컬럼 그룹), label(예측 결과 값과 비교할 train 데이터 안의 count값)
이 때, 변수가 세 개 필요하다.
X_train - count 관련 컬럼 제외한 나머지 feature값
y_train - lable, train데이터의 count값
X_test - test데이터의 feature(이 데이터에는 원래 count가 없다. 이걸 예측해주는 것이 머신러닝이다.)
자, 설정을 했으면 이제 기계를 돌려본다. 디시전 트리라고 하는 머신러닝은 두 가지 기능이 있는데,
classifier, regressor 이렇게 두 개가 있다. 전자는 고정된 값을 분류할 때, 후자는 흐름을 파악할 때 주로 쓴다.
아래와 같이 코드를 입력하면 디시전 트리를 불러온다.
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(random_state=37)
model
그리고 예측하기. 이것을 fit이라고 한다.
fit을 통해 예측한 값(X_train 대비 y_train 결과값을 기준으로 한 X_test 대비 test파일의 count 값. )을
정답지 파일에 넣어주고 저장, 그리고 케글에 제출하면 끝이다.
타이타닉과는 문제의 성질이 다르다. 본질적으로 분류인지, 회귀인지를 판단해 적용하는 것이 중요하다.
디테일한 분석, '탐험적 데이터 분석'은 다음주에 이어진다. 좀 더 집중해야 한다.
머신러닝과 딥러닝의 차이는 아직 잘 모르겠다.
'Data Analysis > DS SCHOOL' 카테고리의 다른 글
DS스쿨 데이터사이언스 입문반 2주차 후기 (0) 2020.05.20